Le Labo #37 | Provisionning de bases SQL avec Liquibase et ArgoCD
21/Apr 2022
Je viens de réaliser que mon tout dernier article date de Juin 2021…presque un an sans publier quoi que ce soit, ça fait long.
Quoi qu’il en soit, cet article a pour objectif d’expliquer comment déployer et provisionner des bases de données SQL avec Liquibase et ArgoCD en mode job.
Avant d’entrer dans la technique, je vais commencer pour expliquer le contexte ainsi que quelques points de détail techniques.
On pourrait croire qu’il n’y a rien de plus simple que de de provisionner une base de données sur un serveur SQL…après tout, il suffit d’exécuter un script SQL pour créer un utilisateur, son mot de passe, lui octroyer des droits sur une base et créer la base en question. Cependant cet article n’aurait pas besoin d’être écrit, ni même publié, s’il n’y avait pas un peu de challenge, car il ne s’agit pas de déployer qu’une seule base de données mais une vingtaine, le tout autour de…plus d’une centaine de schémas de données et jusqu’à six types de données différents. Vous l’avez bien compris…nous n’allons pas aborder du MySQL ou du MariaDB mais du Microsoft SQL Server.

Le besoin
Il s’avère que l’application cible nécessite un jeu de données pour pouvoir démarrer et fonctionner correctement, ce jeu de données « legacy » tourne actuellement sur d’anciens serveurs SQL Server 2008 (en cours de remplacement) et, dans le but de moderniser le déploiement de l’application, nous avons également besoin de repenser le provisionning de la base SQL.
Ce jeu de données comprends les éléments suivants :
- Environ 140 schémas de données,
- Une vingtaine de bases de données différentes,
- Des liens logiques entre serveurs,
- Des systèmes de fichiers logiques,
- Des types de données telles que des tables, triggers, procédures stockées, fonctions et des vues
Tout cela est déployé à l’aide d’un script…à la main (sans même évoquer les bases Cassandra et PostgreSQL) ce qui n’est pas adapté au mode de déploiement ciblé (création d’environnement de déploiement à la volée).
Les ingrédients
J’imagine que vous pensez déjà que je vais aborder Liquibase…Et vous aurez raison, il n’y a plus vraiment besoin de le présenter tellement il fait partie du toolkit du bon développeur d’application web nécessitant une base de données (SQL ou non).
Par contre, comment passer des scripts SQL au déploiement proprement dit ?
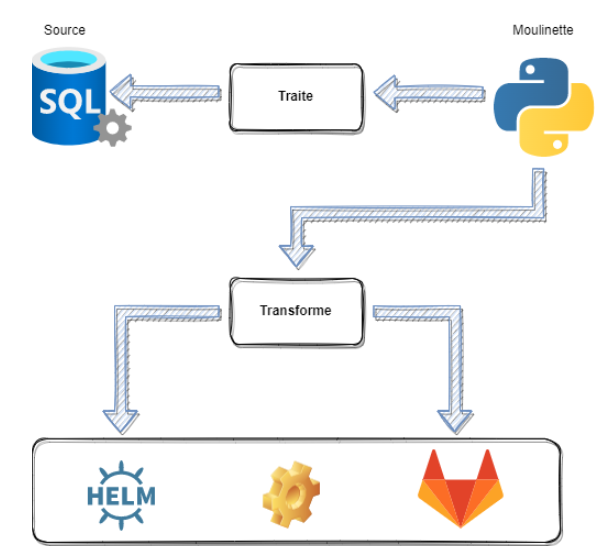
A l’aide de plusieurs technologies :
- Gitlab et Gitlab-CI : nous allons versionner nos scripts SQL et liquibase dessus. Par contre, l’organisation des dépôts sera complètement différente. Ici pas de dépôts par base de données…mais par schéma. Par conséquent, nous aurons au moins 140 dépôts à gérer, mais pas de panique.
- Helm : Chaque schéma sera déployé à l’aide d’un chart Helm et d’un job depuis Kubernetes (potentiellement fonctionnel aussi sur bien sur les services de conteneurs d’Azure, AWS ou Google Cloud), ce qui implique la création d’une image docker et d’un chart Helm spécifique à chaque dépôt.
- Harbor nous servira à enregistrer les images docker ainsi que les values d’environnement spécifique à chaque schéma ainsi que le chart (stocké sur Nexus),
- A l’aide de Liquibase, nous allons générer un changelog par schéma et un changeset par type de données. Chaque changeset se chargeant d’effectuer les appels vers des scripts SQL au format Transact-SQL, le changelog, de son côté, se chargera d’appeler les changeset en fonction d’un certain contexte (dans le cas de plusieurs base de données dans un schéma).
- Microsoft SQL Server, évidemment…
- Et Python…afin de gagner du temps dans le but de générer les « scripts » Liquibase, les values des charts Helm et de pousser tous les updates effectués dans chaque dépôts sur Gitlab. N’oublions pas les 140 dépôts à gérer, imaginez qu’il n’y a pas que 3 ou 4 fichiers dans chacun d’entre eux. L’idée derrière la moulinette à coder est, certes, de perdre un peu de temps au début pour pouvoir en gagner, au final, sur la gestion du « code » Liquibase, Transact-SQL et Helm.
La moulinette
Autant commencer par l’ingrédient probablement le moins fun mais qui a toute son importance dans le processus. Imaginez devoir gérer à la main plus de mille fichiers, c’est chronophage et souvent source d’erreurs.
Je préfère rappeler un autre détail : je ne suis pas développeur python, j’avoue également avoir démarré cette moulinette en bash.
La structure du dump SQL Server sur laquelle j’ai pu mettre la main est la suivante : /racine/database_name/datatype/schema.table_name.sql
Evidemment « table_name » peut être remplacé par « function_name », « storedprocedure_name » ou par autre chose. Néanmoins la structure du dump suit un pattern bien précis qui permet l’automatisation de :
- La création d’une arborescence par dépôts, dans notre cas, le nom du schéma correspondant au nom du dépôt, puis la création de sous-dossiers par type de données et la copie des fichiers correspondants.
def createdir(base_dir):
for dbs in os.listdir(base_dir):
for tds in os.listdir("%s/%s" % (base_dir, dbs)):
for datas in os.listdir("%s/%s/%s" % (base_dir, dbs, tds)):
scs = datas.split(".")
path = "%s/liquibase/%s/%s" % (scs[0],dbs,tds)
try:
os.makedirs(path)
except OSError as error:
pass
for file in glob.glob("%s/%s/%s/%s.*" % (base_dir, dbs, tds, scs[0])):
try:
shutil.copy(file, path)
except OSError as error:
pass
- La création du changeset par type de données,
def generatechangeset(base_dir):
counter = 1
for scs in os.listdir(base_dir):
for dbs in os.listdir("%s/%s/liquibase" % (base_dir, scs)):
for tds in os.listdir("%s/%s/liquibase/%s" %(base_dir, scs, dbs)):
changesetRoot = ET.Element('databaseChangeLog', dbClRoot)
for file in os.listdir("%s/%s/liquibase/%s/%s" % (base_dir, scs, dbs, tds)):
if file.endswith(".sql"):
changeset = ET.SubElement(changesetRoot, 'changeSet',
{'id': str(counter), 'author': '%s_changeset' % tds,
'runOnChange': 'true', 'context': '%s' % dbs})
preConditions = ET.SubElement(changeset, 'preConditions', {'onFail': 'CONTINUE'})
sqlFile = ET.SubElement(changeset, 'sqlFile', {'dbms': 'mssql',
'encoding': 'utf-8',
'endDelimiter': '\\nGO',
'path': '%s/%s/%s' % (dbs, tds, file),
'splitStatements': 'true',
'stripComments': 'true'})
counter += 1
tree = ET.ElementTree(indent(changesetRoot))
tree.write('%s/liquibase/%s/%s_changeset.xml' % (scs, dbs, tds), xml_declaration=True, encoding='utf-8')
- La création du changelog par dépôt.
def generatechangelog(base_dir):
counter = 1
for scs in os.listdir(base_dir):
for dbs in os.listdir("%s/%s/liquibase" % (base_dir, scs)):
changelogRoot = ET.Element('databaseChangeLog', dbClRoot)
try:
for tds in os.listdir("%s/%s/liquibase/%s" % (base_dir, scs, dbs)):
if tds.endswith(".xml"):
includeFile = ET.SubElement(changelogRoot, 'include', {'file': 'liquibase/%s/%s' % (dbs, tds),
'context': '%s' % dbs})
counter += 1
tree2 = ET.ElementTree(indent(changelogRoot))
tree2.write('%s/%s/changelog.xml' % (base_dir, scs), xml_declaration=True, encoding='utf-8')
except OSError as error:
continue
J’ai également remarqué un détail dans le nom de chaque schema : certains sont en majsucle, d’autre en minuscule, quelques uns avec la première lettre en majsucule et très peu écrits de manière « hybride » (mix entre majuscule et minuscule). Or, lors de la création des dépôts dans Gitlab, nous étions confrontés à une contrainte de nommage assez particulière qui rendait impossible la création de dépôts avec un nom identique en minuscule.
Dans la pratique, chaque dépôt créé avec un nom en majuscule/titre sera tout de même en minuscule lors du clonage en local du dépôt.
Première difficulté rencontrée…mais pas de panique, il y a toujours un moyen de contourner cette limitation en codant une pirouette au sein de la moulinette.
Par la suite, j’ai également eu à coder :
- La génération des values des charts Helm de chaque schéma, incluant les configmaps et les secrets,
from pathlib import Path
import click, jinja2, random, sys, string, json
@click.command()
@click.option('-f', '--file')
@click.option('-e', '--env')
def templates(file, env):
templateEnv = jinja2.Environment(loader=jinja2.FileSystemLoader(
searchpath="/home/mike/SQLSERVER/sqlserver-ci-cd/templates/"), trim_blocks=True, lstrip_blocks=True)
template = templateEnv.get_template("values.yaml.jinja2")
datas = json.load(open(file, 'r'))
for schema in datas:
for data in datas[schema]:
file = Path("%s_values.yaml" % (schema))
with open(file, 'w') as f:
f.write(template.render(database=data["database"], env=env, schema=schema))
f.close()
if __name__ == '__main__':
templates()
- Le push de chaque dépôt vers gitlab…afin d’automatiser cette partie.
def gitactions(base_dir, target_dir, env):
for dir in os.listdir(base_dir):
try:
os.system("git -C %s/%s add ." % (target_dir, dir))
os.system("git -C %s/%s commit -m 'Update for new files - %s'" % (target_dir, dir, datetime.now().time()))
os.system("git -C %s/%s push origin %s" % (target_dir, dir, env))
except OSError as error:
pass
Gitlab-CI
Une fois tout le code versionné sur Gitlab, il nous fallait pouvoir continuer à travailler, avec en but final, de déployer notre code T-SQL sur le serveur cible.
Avec Gitlab-CI (nous aurions pu utiliser Jenkins, Travis-CI ou n’importe quel autre outil de CI-CD) l’objectif était de pouvoir :
- Construire une image Docker de chaque repo incluant les codes Liquibase et T-SQL,
- D’inclure dans chaque image le chart Helm complet (les templates provenant de Nexus ainsi que les values par environnement),
- De publier le Chart Helm et l’image Docker sur Harbor dans le but de réutiliser le tout sur ArgoCD.
Dans ce but, nous avons utilisé deux dépôts différents, le premier pour versionner certaines fonctions de notre pipeline (à la manière des shared libraries de Jenkins), le second pour “consommer” ces fonctions via l’utilisation d’une balise “include”.dans chaque dépôt relatifs aux schema de base de données.
Le pipeline appelé :
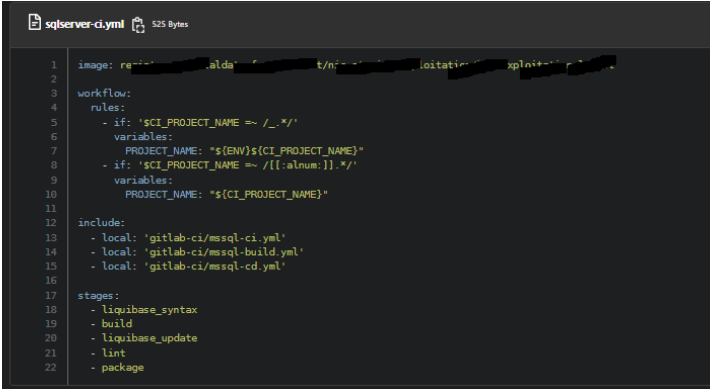
D’un côté, cela permet de gérer son code depuis un seul dépôt…par contre, la moindre mise-à-jour mal maîtrisée peut avoir des conséquences dramatiques et causer des erreurs en série.
Mais ce n’est pas tout…nous avions également un autre dépôt dans lequel les Charts ArgoCD, des manifests au format yaml (similaire à ceux de Kubernetes), seraient versionnés et déployés automatiquement.
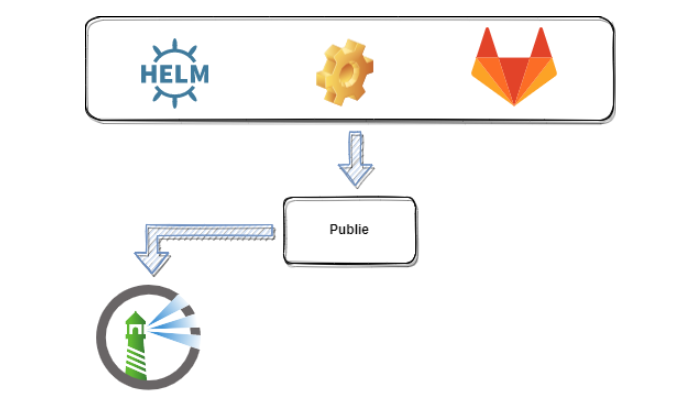
Helm
Je pense ne plus avoir besoin d’expliquer ce qu’est Helm ou à quoi il peut servir. Il s’agit bien évidemment d’un gestionnaire de package dédié au déploiement d’objets sur Kubernetes. Les objets en question peuvent être des daemonset, des replicaset, des operators, des services, etc.
Dans notre cas, nous allons déployer des jobs.
Pas des Pods, des services, des statefulset ni même des cronjob…mais de simple jobs.
En terminologie Kubernetes, un job crée un ensemble de pods qui s’exécute autant de fois que désiré (dans la définition du job) et une fois que l’exécution s’est achevée avec succès, Kubernetes conserve la trace de l’exécution.
Puisqu’il s’agit d’exécution de Pods, la définition d’un Job est relativement similaire à celle d’un deployment.
Petite précision : un Chart Helm ne contenant pas de pods étant déjà disponible sur Nexus, un petit travail d’adaptation était nécessaire pour que notre Job puisse être fonctionnel.
C’est également a ce moment qu’entre un autre dépôt Gitlab sur lequel est versionné le code du Chart ainsi que le pipeline permettant de le publier sur Harbor.
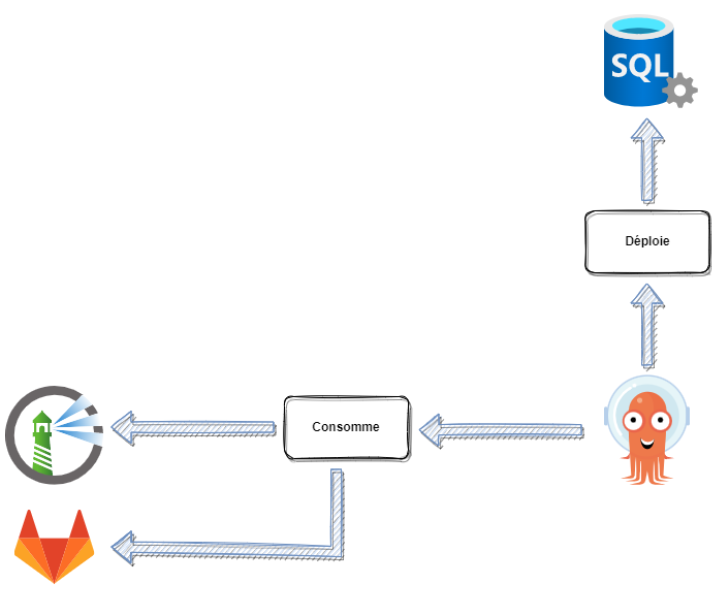
ArgoCD
Avec ArgoCD, j’entre dans le vif du sujet du déploiement des données sur le serveur SQL. L’interface utilisateur d’ArgoCD est relativement épurée et ne présente que quatre menus sur la gauche :
- Manage your applications, and diagnose health problems : Ce sera depuis cet écran que l’on va déployer nos “applications” (terme technique propre à ArgoCD).
- Manage your repositories, project and settings : Sur cet écran, on retrouve les fameux dépôts depuis lesquelles les applications seront déployées, mais également tout l’aspect configuration d’ArgoCD,
- User Info : L’écran d’informations relatives à l’utilisateur connecté ou bien, dans le cas ou un administrateur serait connecté, la gestion des utilisateurs.
- Read the documentation, and get help and assistance…
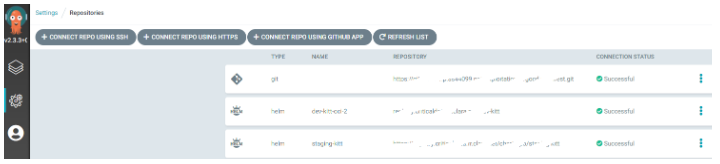
La configuration du dépôt Harbor sur lequel sont enregistrés les charts Helm de chaque schéma de de données est simple, via l’écran Settings / Repositories (le second menu sur la gauche) :
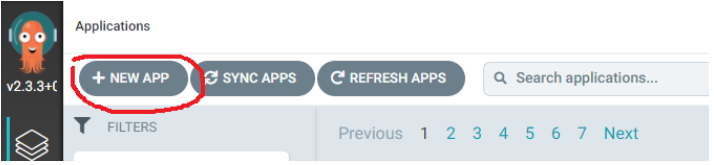
Grâce à l’assistant de déploiement d’application, la maintenance des éléments déployés est simple et, souvent, automatique en fonction des options sélectionnés durant la phase de création (via les sync options) :

Lors de la phase de création d’application, une option “Edit as YAML” est présente (en haut à droite) et nous permettra d’éditer le chart ArgoCD et de le versionner dans un dépôt git prévu à cet effet. Dépôt git qui nous servira, par la suite, à redéployer automatiquement l’application en cas de mise-à-jour du dépôt originel.
Finalement
Il est vrai que, maintenir une base SQL à l’aide d’ArgoCD et de Liquibase est d’une simplicité enfantine si l’on met de côté les points de blocages que l’on peut rencontrer. Certains peuvent décourager certains de se lancer dans un projet tels que celui-ci, notamment en raison de la complexité de liquibase qui peut gérer plusieurs types de format de syntaxe différents et qui, au final, ne fonctionnent pas tous de la même manière.
De plus, gérer un grand nombre de données est chronophage, automatiser la gestion de celles-ci à l’aide d’une moulinette à code soi-même (quel que soit le langage de scripting utilisé) peut l’être encore plus (et peu importe son degré de maîtrise).
Troisième point à aborder, la mise à jour des données par les développeurs à acculturer sur l’utilisation de Liquibase…quand il ne sont pas complètement hermétiques à ce type de changement.