Le Labo #30 | Ejabberd et l'autoscaling sur AWS
26/Aug 2020
A l’origine
Je vais vous avouer que lorsque l’on m’a demandé si je connaissais le protocole XMPP, j’avais un doute mais je me suis renseigné avant de répondre.
Et c’est à ce moment que ça m’est revenu (en parcourant les résultats proposés par Google): Jabber est basé sur le protocole XMPP.
Pour la petite anecdote, j’ai évolué pendant plusieurs années pour un fournisseur de services Cloud Européen dans lequel nous utilisions Jabber pour communiquer entre les différentes équipes (Italie, France, Europe de l’est).
Après avoir effectué une petite recherche sur les middlewares relatifs à l’exploitation d’un service basé sur ce protocole, j’en ai relevé quelques uns:
- eJabberd, le seul qui soit disponible sur tous les systèmes d’exploitation et complètement opensource et disposant d’une documentation extrêmement complète,
- IoT Broker, disponible uniquement sur Windows,
- Isode M-Link, disponible sur Windows et Linux…mais non open-source,
- Prosody, disponible sur les systèmes Unix/Linux (y compris MacOs),
- Tigase, disponible sur tous les systèmes d’exploitation, y compris Solaris.
Pour cet article, j’ai choisi de me pencher sur eJabberd et sur son fonctionnement.
L’idée
Après avoir lu un bonne partie de la documentation, je peux partir sur le constat suivant: ejabberd est stable, très stable, et peut héberger près de deux millions d’utilisateurs du moment qu’il ne tourne pas sur un serveur asthmatique. Par contre, aucune indication de ce que peut être un serveur asthmatique (c’est de moi, ça ne vient pas du tout de la documentation officielle).
J’imagine que tout dépend de l’activité des utilisateurs sur le serveur ainsi que des modules actifs.
Il y a toute une liste de Use Cases possibles sur le site officiel, ce qui laisse imaginer des recommandations techniques relativement élevées en fonction des cas.
Si vous avez eu, tout comme moi, l’idée de parcourir la documentation, vous avez certainement remarqué la partie clustering qui reste tout de même limitée car non automatique.
Le but de cet article est de découvrir comment le rendre complètement automatique.
#Le besoin Comme évoqué plus haut, la documentation de eJabberd est très claire même au niveau du clustering. Bien que cette partie ne soit pas complètement automatique, il est tout à fait possible d’automatiser l’ajout de workers et de les supprimer.
Au niveau middleware
A ce niveau là, rien à signaler car seul l’exécutable est nécessaire, chaque serveur de l’autoscaling group se connectera au master grâce à un StartupScript contenant toutes les commandes de l’installation au démarrage du service en passant par la configuration (certes assez basique) du service:
Sur le Master
#!/bin/bash
sudo wget https://www.process-one.net/downloads/downloads-action.php?file=/20.07/ejabberd_20.07-0_amd64.deb -O /opt/ejabberd_20.07-0_amd64.deb
sudo dpkg -i /opt/ejabberd_20.07-0_amd64.deb
NODE=$(hostname -s)
sudo sed -i 's/#ERLANG_NODE=ejabberd@localhost/ERLANG_NODE=ejabberd@'$NODE'/g' /opt/ejabberd/conf/ejabberdctl.cfg
sudo sed -i 's/#FIREWALL_WINDOW=/FIREWALL_WINDOW=4200-4300/g' /opt/ejabberd/conf/ejabberdctl.cfg
sudo cp /opt/ejabberd-20.07/bin/ejabberd.service /lib/systemd/system sudo systemctl daemon-reload
sudo systemctl start ejabberd
Sur les workers
#!/bin/bash
sudo wget https://www.process-one.net/downloads/downloads-action.php?file=/20.07/ejabberd_20.07-0_amd64.deb -O /opt/ejabberd_20.07-0_amd64.deb
sudo dpkg -i /opt/ejabberd_20.07-0_amd64.deb
NODE=$(hostname -s)
sudo sed -i 's/#ERLANG_NODE=ejabberd@localhost/ERLANG_NODE=ejabberd@'$NODE'/g' /opt/ejabberd/conf/ejabberdctl.cfg
sudo sed -i 's/#FIREWALL_WINDOW=/FIREWALL_WINDOW=4200-4300/g' /opt/ejabberd/conf/ejabberdctl.cfg
sudo cp /opt/ejabberd-20.07/bin/ejabberd.service /lib/systemd/system
**sudo scp root@master:/opt/ejabberd/.erlang.cookie /opt/ejabberd/.erlang.cookie**
**sudo chown ejabberd:ejabberd /opt/ejabberd/.erlang.cookie**
**sudo chmod 400 /opt/ejabberd/.erlang.cookie**
sudo systemctl daemon-reload
sudo systemctl start ejabberd
sudo /opt/ejabberd-20.07/bin/ejabberdctl --no-timeout join_cluster ejabberd@'MASTER'
La différence majeure entre le master et les workers se situe au niveau du cookie à copier du premier vers les seconds (voir la zone en surbrillance sur le script de démarrage dédié aux workers).
Il reste un détail qui a son importance: comment est-ce qu’un worker peut quitter le cluster?
Sur les instances EC2, il est possible de définir un ShutdownScript qui s’exécute dès la suppression d’une instance présente dans un autoscaling group.
Au niveau infrastructure
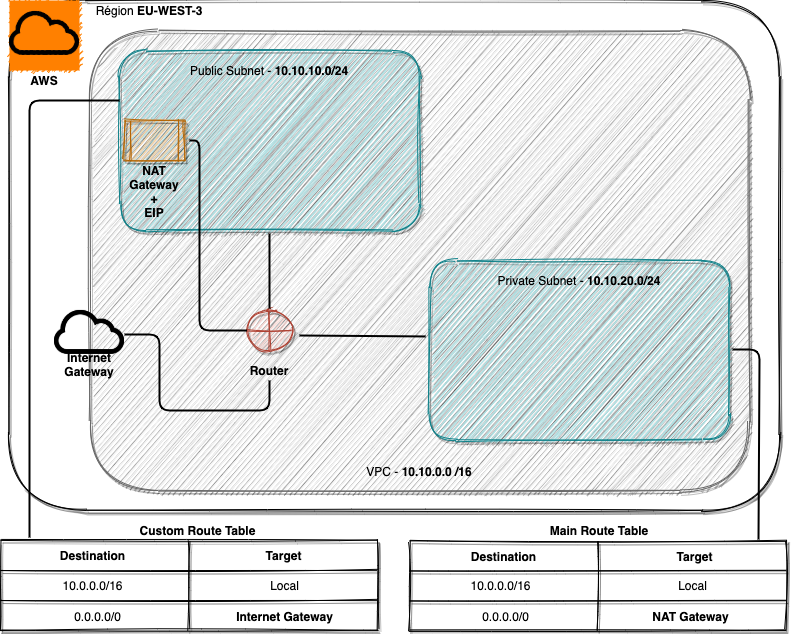
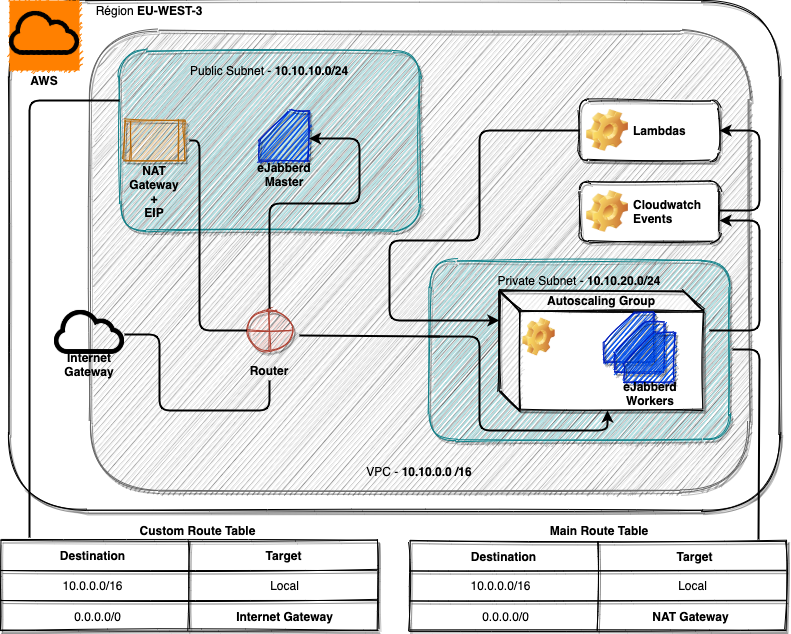
Comme pour déployer un loadbalancer, j’avais prévu de configurer le service VPC avec:
- Deux subnets, un privé (ne contenant que les workers) et un public,
- Un Security Group (ouvrant le port 22 et ceux relatifs à eJabberd),
- Une seule adresse IP publique (afin que le seul point d’entrée soit le master eJabberd),
- La NAT Gateway ainsi que les règles de routage (afin que les instances du subnet privé puissent accéder à Internet dans le but de télécharger l’archive de eJabberd).
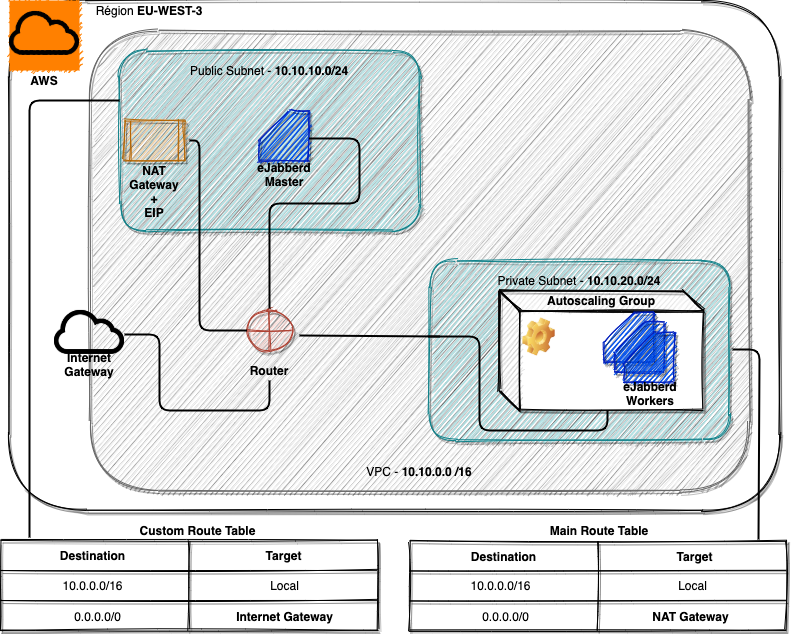
Au niveau des instances
Sur ce point, pas de très grosses surprises: un master et plusieurs workers au sein d’un groupe d’instances en mode autoscaling. L’avantage de ce dernier est de pouvoir répondre à la charge du moment en procédant à un équilibrage de la charge de manière horizontale (en ajoutant des instances, au contraire de l’autoscaling vertical qui effectue un ajustement des ressources mémoire et processeur).
Et le reste ?
Je n’ai pas encore évoqué certains services tels que Cloudwatch Events ainsi que les Lambdas. Pour cet article, ces derniers vont être utilisés uniquement pour le ShutdownScript qui sera en charge de faire quitter le cluster eJabberd à une instance de l’autoscaling group lors du scale down …en lançant la commande suivante:
sudo /opt/ejabberd-20.07/bin/ejabberdctl leave_cluster 'ejabberd@[HOSTNAME]'
Ce type de configuration requiert tout d’abord la création d’une règle sur Cloudwatch Events ainsi que la target qui lui sera associée:
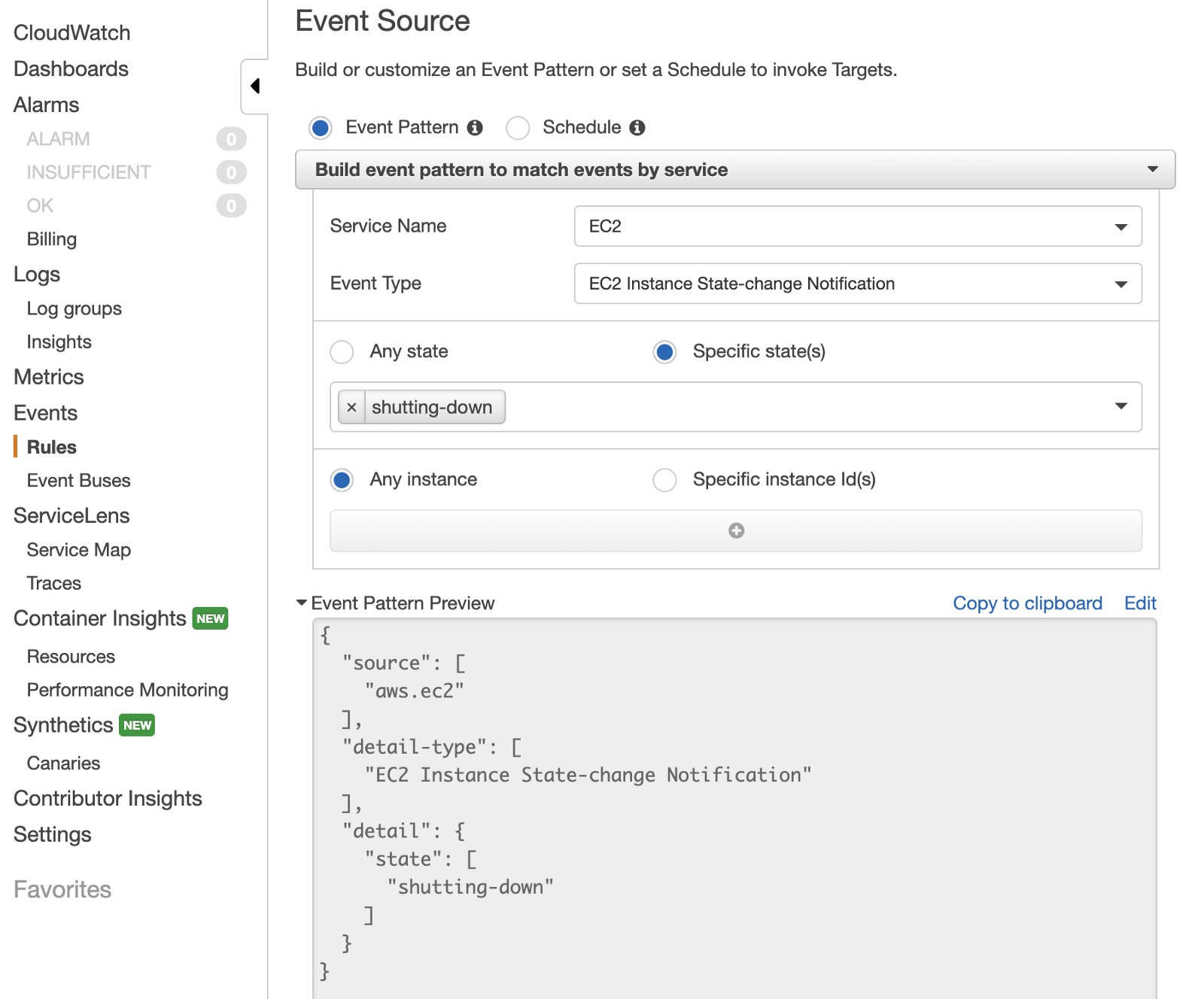
Pour créer une règle, il suffit juste de suivre le guide Build event pattern, la fenêtre de Preview ajoutera la sélection parmi les services et les types d’événements.
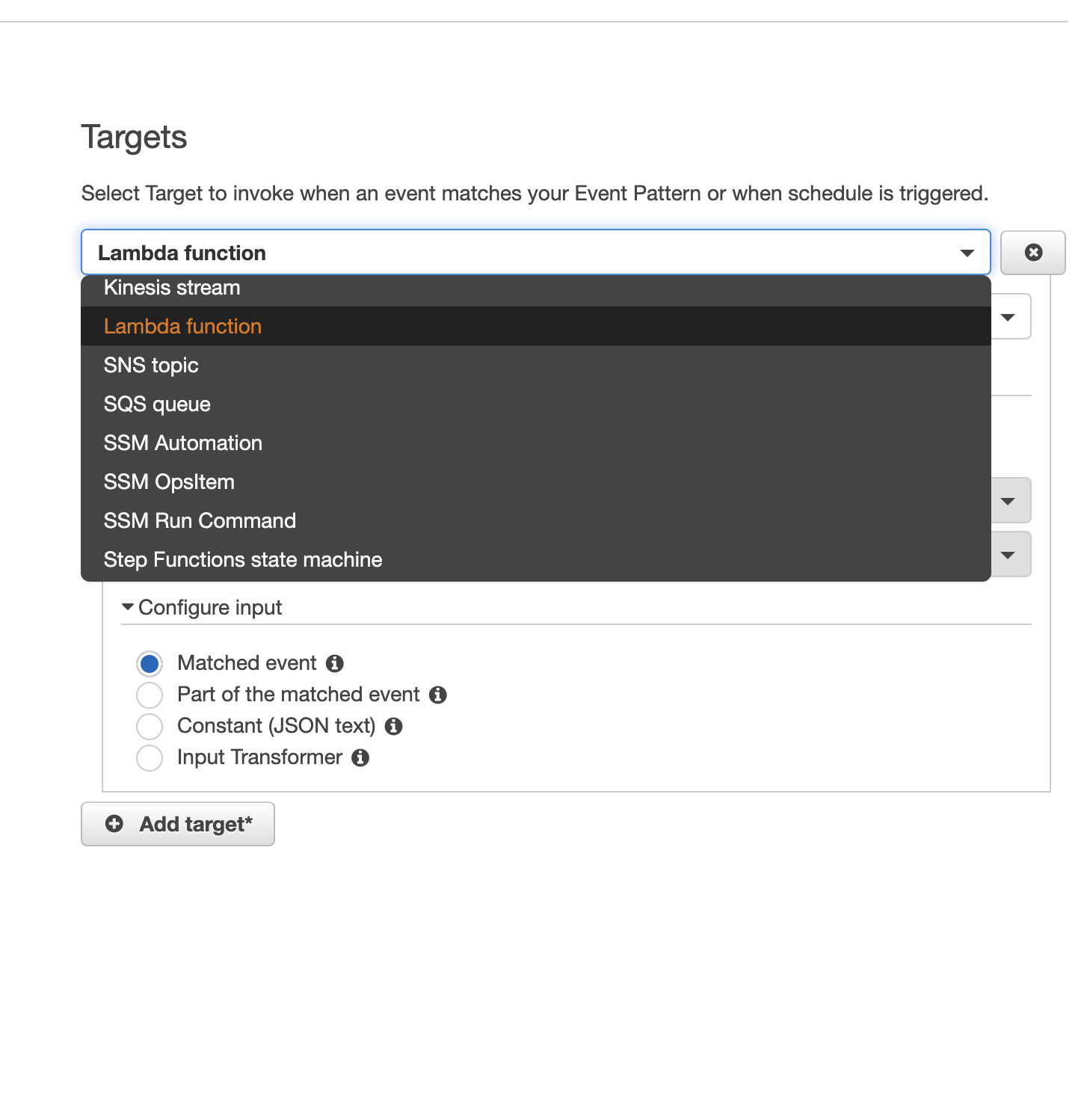
Dans la seconde partie du même écran (ci-dessous), se trouve le ou les triggers à définir…et il y a du choix entre Kynesis, Lambdas, Notifications (SNS), Messaging Queue (SQS), System Manager ou Step Functions. Mon choix s’est porté sur les Lambdas dans le but d’éviter de passer par un autre service et d’exécuter directement les commandes via SSH sur le serveur en question.
Une fois déployé?
Une fois que tout est prêt, l’infrastructure ressemble à ce qui suit et vous pourrez également vous connecter à l’interface (http://[MASTER_IP ou DNS_NAME]:5280/admin) du master eJabberd à l’aide des credentials que vous aurez définis durant l’installation.
Et si on veut aller plus loin ?
Bien que j’ai poussé un peu plus loin un cas d’utilisation classique de eJabberd (rare sont les cas d’utilisation classique utilisant des fonctions d’autoscaling), il est possible d’aller encore plus loin et ce sur plusieurs niveaux:
- Sécurité
- Configuration
- Base de données
Pour tout ce qui est Sécurité, je fais bien entendu référence au fait que eJabberd peut se connecter à un serveur LDAP pour tout ce qui est gestion des utilisateurs…mais il n’y a pas que ça et tout est documenté sur le site officiel (même si c’est fait de façon assez sommaire et peu détaillé).
Pour le reste de la configuration, c’est également le cas: documenté de manière basique sur le site officiel mais en creusant un peu sur Internet on trouve des informations ou des tutoriels.